확률적 경사 하강법 - SGD(Stochastic Gradient Descent)
최적의 매개변수 값을 찾는 단서로 매개변수의 기울기(미분)을 이용. 매개변수의 기울기를 구해, 기울어진 방향으로 매개변수 값을 갱신하는 일을 계속 반복한다.
W <- W - ( learning rate * dL / dW )
W : 가중치
L : 손실 함수 심하게 굽이진 움직임을 보여준다. 따라서 이러한 경우에는 조금 비효율 적이다.

머신러닝과 딥러닝을 위한 플랫폼은 Tensorflow, Theano, Pytorch, mxnet, keras, scikit-learn, NLTK 등 여러 종류가 있는데, 이 중에서도 가장 많은 사용자를 확보한 플랫폼이 텐서플로우이다. 텐서플로우는 우수한 기능과 서비스를 제공할 뿐만 아니라 병렬처리를 잘 지원하고, 고급 신경망 네트워크 모델을 쉽게 구현할 수 있기 때문에 인기가 많다.
< 실습예제 >
금융상품 갱신 여부 예측하는 ANN
Churn_Modelling.csv 파일을 보면, 고객 정보와 해당 고객이 금융상품을 갱신했는지 안했는지의 여부에 대한 데이터가 있다.
이 데이터를 가지고 갱신여부를 예측하는 딥러닝을 구성하시오.
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
%matplotlib inline
import os
from google.colab import drive
drive.mount('/content/drive')
os.chdir('/content/drive/MyDrive/kdigital2/deeplearning/data')
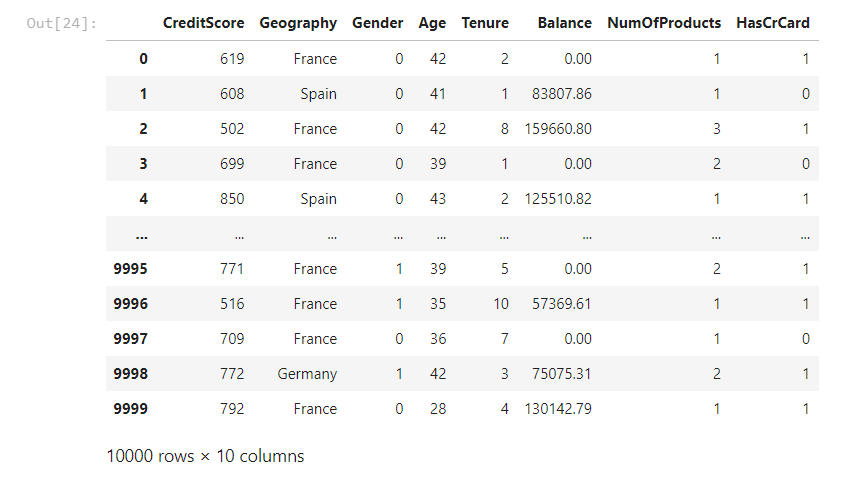
df = pd.read_csv('Churn_Modelling.csv')# nan 있는지 확인# X, y 로 분리df.head()y = df['Exited']X = df.iloc[ : , 3: -2+1]X.head()
# 문자열 데이터는 숫자로 바꿔줘야 한다.X.head()일단 X.head()로 간략히 살펴본다.
X['Geography'].nunique()out : 3
X['Gender'].nunique()out : 2
from sklearn.preprocessing import LabelEncoder
l_encoder = LabelEncoder()
X['Gender'] = l_encoder.fit_transform( X['Gender'] )
X
out
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
ct = ColumnTransformer( [ ('encoder', OneHotEncoder(), [1]) ] ,
remainder= 'passthrough' )
X = ct.fit_transform(X)
X
out

df.describe()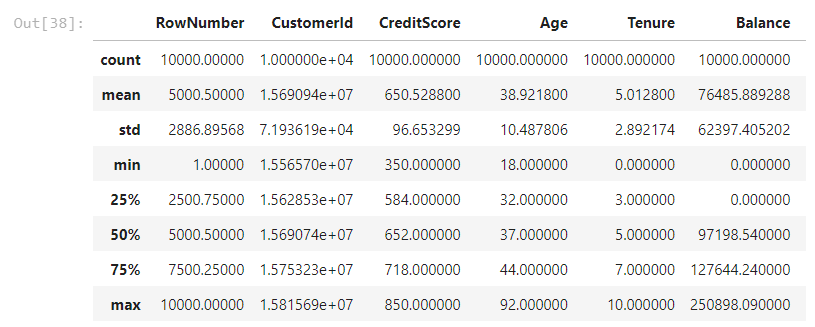
# 피처 스케일링 한다.
from sklearn.preprocessing import MinMaxScaler
sc_X = MinMaxScaler()
X = sc_X.fit_transform(X)
# 학습용과 검증용으로 데이터를 나눈다
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
X_train.shape
X_test.shape
y_train.shape
y_test.shape
X_train[0, : ]
out

# Part 2 - Now let's make the ANN!
import tensorflow as tf
from tensorflow import keras
from keras.models import Sequential
from keras.layers import Densemodel = Sequential()
model.add( Dense(units = 6, activation='relu', input_shape = (11,) ) )
model.add( Dense(units= 8 , activation= tf.nn.relu ) )
model.add( Dense(units= 1, activation= 'sigmoid' ) )
# compile
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']
model.summary()
out

model.fit(X_train, y_train, epochs = 20, batch_size = 10)
out
Epoch 1/20
800/800 [==============================] - 3s 2ms/step - loss: 0.5531 - accuracy: 0.7640
Epoch 2/20
800/800 [==============================] - 2s 2ms/step - loss: 0.4847 - accuracy: 0.7960
Epoch 3/20
800/800 [==============================] - 2s 2ms/step - loss: 0.4562 - accuracy: 0.7993
Epoch 4/20
800/800 [==============================] - 2s 2ms/step - loss: 0.4427 - accuracy: 0.8050
Epoch 5/20
800/800 [==============================] - 2s 2ms/step - loss: 0.4368 - accuracy: 0.8100
Epoch 6/20
800/800 [==============================] - 2s 2ms/step - loss: 0.4316 - accuracy: 0.8129
Epoch 7/20
800/800 [==============================] - 2s 2ms/step - loss: 0.4274 - accuracy: 0.8140
Epoch 8/20
800/800 [==============================] - 2s 2ms/step - loss: 0.4239 - accuracy: 0.8164
Epoch 9/20
800/800 [==============================] - 2s 2ms/step - loss: 0.4210 - accuracy: 0.8200
Epoch 10/20
800/800 [==============================] - 2s 2ms/step - loss: 0.4186 - accuracy: 0.8216
Epoch 11/20
800/800 [==============================] - 2s 2ms/step - loss: 0.4154 - accuracy: 0.8256
Epoch 12/20
800/800 [==============================] - 1s 1ms/step - loss: 0.4121 - accuracy: 0.8276
Epoch 13/20
800/800 [==============================] - 1s 1ms/step - loss: 0.4086 - accuracy: 0.8296
Epoch 14/20
800/800 [==============================] - 1s 1ms/step - loss: 0.4024 - accuracy: 0.8319
Epoch 15/20
800/800 [==============================] - 1s 1ms/step - loss: 0.3970 - accuracy: 0.8359
Epoch 16/20
800/800 [==============================] - 1s 1ms/step - loss: 0.3906 - accuracy: 0.8367
Epoch 17/20
800/800 [==============================] - 1s 2ms/step - loss: 0.3848 - accuracy: 0.8390
Epoch 18/20
800/800 [==============================] - 2s 2ms/step - loss: 0.3804 - accuracy: 0.8416
Epoch 19/20
800/800 [==============================] - 2s 2ms/step - loss: 0.3767 - accuracy: 0.8429
Epoch 20/20
800/800 [==============================] - 1s 2ms/step - loss: 0.3725 - accuracy: 0.8411
# 모델 평가model.evaluate(X_test, y_test)
out
63/63 [==============================] - 0s 1ms/step - loss: 0.3624 - accuracy: 0.8530
[0.3624242842197418, 0.8529999852180481]
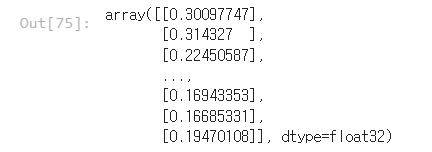
# 컨퓨전 매트릭스 확인from sklearn.metrics import confusion_matrix, accuracy_score
y_pred = model.predict(X_test)
y_pred
out
y_pred = (y_pred > 0.5).astype(int)
y_pred
out
array([[0],
[0],
[0],
...,
[0],
[0],
[0]])
X_testout
array([[1. , 0. , 0.494 , ..., 1. , 1. ,
0.96429754],
[0. , 0. , 0.346 , ..., 1. , 0. ,
0.64351406],
[0. , 1. , 0.712 , ..., 1. , 1. ,
0.37863951],
...,
[0. , 1. , 0.456 , ..., 1. , 0. ,
0.70767563],
[1. , 0. , 0.6 , ..., 1. , 1. ,
0.05632988],
[1. , 0. , 0.446 , ..., 1. , 0. ,
0.96478724]])
y_test
out
9394 0
898 1
2398 0
5906 0
2343 0
..
1037 0
2899 0
9549 0
2740 0
6690 0
Name: Exited, Length: 2000, dtype: int64
cm = confusion_matrix( y_test, y_pred)
cm
out
array([[1537, 58],
[ 236, 169]])
(1537+169) / cm.sum()out
0.853
in
accuracy_score(y_test, y_pred)
out
0.853
'Deep Learning' 카테고리의 다른 글
| Deep Learning : EarlyStopping 라이브러리 사용법 (0) | 2022.06.13 |
|---|---|
| Deep Learning : validation data란 무엇이고, code에서 사용하는 방법 / 파라미터 validation_split (0) | 2022.06.13 |
| Deep Learning : learning rate를 옵티마이저에서 셋팅하는 코드 / 실습문제 풀기 (0) | 2022.06.13 |
| Deep Learning : 텐서플로우에서 학습시 epoch와 batch_size에 대한설명 (0) | 2022.06.10 |
| Deep Learning with Neural Networks (0) | 2022.06.09 |

