
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
%matplotlib inline
import platform
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False
if platform.system() == 'Darwin':
rc('font', family='AppleGothic')
elif platform.system() == 'Windows':
path = "c:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('Unknown system... sorry~~~~')( 파일명 age.csv , encoding='cp949' )
불러오는 방법
df = pd.read_csv('data/age.csv' , encoding='cp949',thousands= ',')
# 따옴표는 문자기 때문에 이런 코드를 작성해줘야한다.
df.index_col=0
df실습 1. '삼청동' 의 인구 구조를, 0세부터 100세 까지 나이대 별로 몇명이 있는지 시각화 하세요.
- 가로축은 나이, 세로축은 인구수
df.head()data = df.loc[df['행정구역'].str.contains('삼청동'), '2019년07월_계_0세' : ]
data
x = np.arange(0, 100+1)
y = data.values.reshape(101,)
plt.plot( x , y )
plt.show()결과
data = df.loc[df['행정구역'].str.contains('삼청동'), '2019년07월_계_0세' : ]
x = np.arange(0, 100+1)
y = data.values.reshape(101,)
plt.plot( x , y )
plt.title('삼청동')
plt.show()결과
data = df.loc[df['행정구역'].str.contains('종로구'), '2019년07월_계_0세' : ]
data = data.iloc[0 , ]
x = np.arange(0, 100+1)
y = data.values.reshape(101,)
plt.plot( x , y )
plt.title('종로구')
plt.show()결과
실습 3. 위의 '연수구' 의 인구 구조를, 만0세, 15, 25, 35, 45세 까지 5개 파이차트로, 각 인구수를 시각화 하세요.
( 파이차트로 )
data = df.loc[df['행정구역'].str.contains('연수구'), '2019년07월_계_0세' : ]
data = data.iloc[0 , ]
data = data[ [0 , 5 , 15, 25, 35, 45]
data
2019년07월_계_0세 2532
2019년07월_계_5세 3684
2019년07월_계_15세 4018
2019년07월_계_25세 4957
2019년07월_계_35세 5162
2019년07월_계_45세 6780
Name: 871, dtype: int64
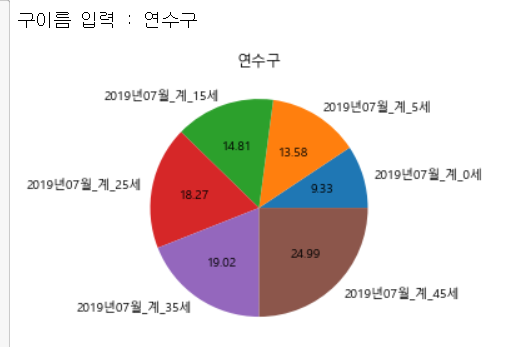
gu_name = input('구이름 입력 : ')
data = df.loc[df['행정구역'].str.contains(gu_name), '2019년07월_계_0세' : ]
data = data.iloc[0 , ]
data = data[ [0 , 5 , 15, 25, 35, 45] ]
plt.pie(data , autopct='%.2f', labels =data.index)
plt.title(gu_name)
plt.show()결과
실습문제
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
%matplotlib inline1. CCTV_in_Seoul.csv 파일을 pandas 로 읽어오세요.
encoding='utf-8' 옵션을 넣습니다.
CCTV_Seoul = pd.read_csv('data/CCTV_in_Seoul.csv',encoding='utf-8')
CCTV_Seoul결과

2. 컬럼 중 "기관명" 컬럼명을 "구별" 로 이름을 바꾸세요.
CCTV_Seoul.rename(columns = {'기관명' : '구별'} , inplace = True)
CCTV_Seoul결과

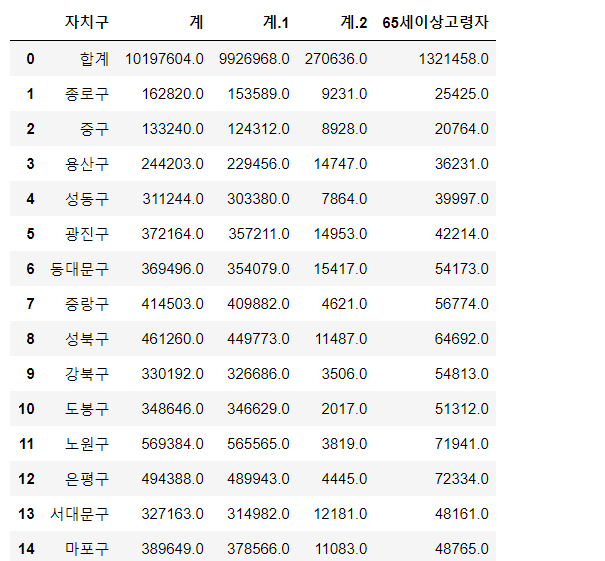
3. population_in_Seoul.xls 파일을 읽으세요.
encoding='utf-8' 옵션을 넣습니다.
pop_color = pd.read_excel('data/population_in_Seoul.xls',
header = 2, usecols = 'B, D, G, J, N' )
pop_color결과
레퍼런스 : 파이썬으로 데이터 주무르기
서울시 구별 범죄 발생과 검거율 데이터 분석
'서울시 관서별 5대 범죄 발생 검거 현황' 파일을 가지고 분석합니다.
* 파일 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
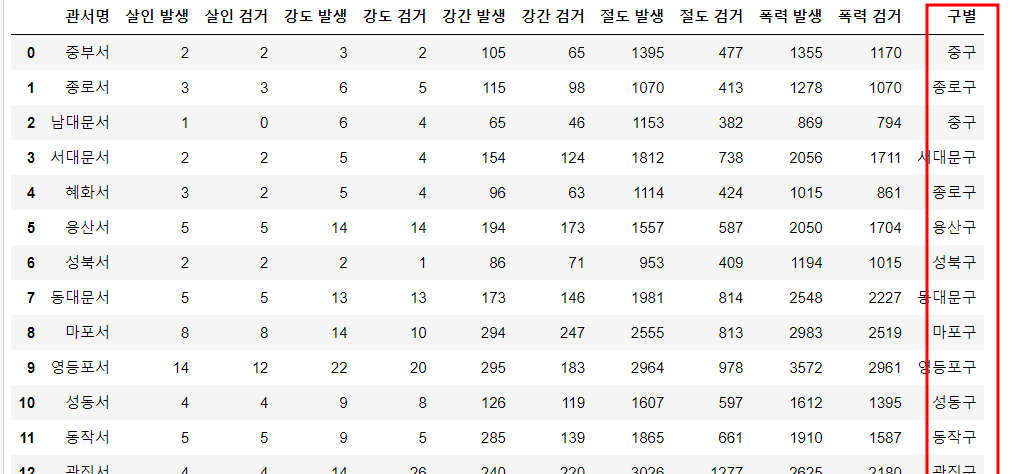
%matplotlib inline실습 1. crime_in_Seoul.csv 파일을 pandas 로 읽어오세요.
한글이 깨지지 않도록 encoding='euc-kr' 옵션을 넣습니다.
df = pd.read_csv('data/crime_in_Seoul.csv' , encoding='euc-kr' thousands= ',')
df.head(3)
df.describe()
실습 2. 경찰서들은 하나의 구에 여러개가 있을 수 있습니다. 따라서 우리는 구 단위로 데이터를 통합하겠습니다.
실습 2-1. 구글 맵 API 를 이용해서, 경찰서가 무슨 구에 있는지 확인하기 위해
아나콘다 프롬프트웨어 다음을 실행. pip install googlemaps
설치방법
1. 아나콘다 프롬프트 검색하여 열기-> 검은 창이 나옴 -> pip install googlemaps을 친다.

그럼 이렇게 나온다.
설치 끝
실습 2-2. 구글 클라우드의 MAPS API 페이지로 이동하여, API 키를 생성합니다.
https://cloud.google.com/maps-platform/?hl=ko
콘솔로 이동 => Geocoding API 선택 => 사용자인증정보 에서 API 키 생성
- 구글 맵스를 사용해서 경찰서의 위치(위도, 경도) 정보를 받아온다
- 이같은 것을 JSON 이라고한다.
- 사용 예 EX) 배달의민족 - 위치경도 등
- json online editor 참고
import googlemaps
gmaps_key = "AIzaSyCRNpyrML6AAW-VA6LuxX49_hU3QGdMnRE" # 자신의 key를 사용합니다.
gmaps = googlemaps.Client(key=gmaps_key)
# API 호출 (API CALL)
gmaps.geocode('서울중부경찰서', language='ko')
[{'address_components': [{'long_name': '27',
'short_name': '27',
'types': ['premise']},
{'long_name': '수표로',
'short_name': '수표로',
'types': ['political', 'sublocality', 'sublocality_level_4']},
{'long_name': '중구',
'short_name': '중구',
'types': ['political', 'sublocality', 'sublocality_level_1']},
{'long_name': '서울특별시',
'short_name': '서울특별시',
'types': ['administrative_area_level_1', 'political']},
{'long_name': '대한민국',
'short_name': 'KR',
'types': ['country', 'political']},
{'long_name': '100-032',
'short_name': '100-032',
'types': ['postal_code']}],
'formatted_address': '대한민국 서울특별시 중구 수표로 27',
'geometry': {'location': {'lat': 37.56361709999999, 'lng': 126.9896517},
'location_type': 'ROOFTOP',
'viewport': {'northeast': {'lat': 37.5649660802915,
'lng': 126.9910006802915},
'southwest': {'lat': 37.5622681197085, 'lng': 126.9883027197085}}},
'partial_match': True,
'place_id': 'ChIJc-9q5uSifDURLhQmr5wkXmc',
'plus_code': {'compound_code': 'HX7Q+CV 대한민국 서울특별시',
'global_code': '8Q98HX7Q+CV'},
'types': ['establishment', 'point_of_interest', 'police']}]----- 주의사항 -----
* 정확한 지명으로 바꿔서, API를 호출해야 한다.
문제
1. 관서명 컬럼에 있는 값들을 가져와서,
2. 왼쪽에는 '서울'이라고 붙이고, 오른쪽에는 '경찰서'라고 붙인다.
name_seires = '서울' + df['관서명'].str[ : -2+1 ] + '경찰서'
station_name = name_seires.to_list()
station_name결과

문제 2
1. station_name 리스트에 있는, 경찰서명칭을, 구글 맵 API에 넣어서 호출한다.
gmaps_key = "AIzaSyCRNpyrML6AAW-VA6LuxX49_hU3QGdMnRE" # 자신의 key를 사용합니다.
gmaps = googlemaps.Client(key=gmaps_key)
# API 호출 (API CALL)
gmaps.geocode('서울중부경찰서', language='ko')문제 3
1. station_names 라는 리스트로 만드세요.
name_seires = '서울' + df['관서명'].str[ : -2+1 ] + '경찰서'
station_name = name_seires.to_list()
station_name
문제 4
1. 주소를 불러온다.
station_address = []
for name in station_name : # '서울중부경찰서'
result = gmaps.geocode(name, language='ko')
if len(result) != 0 :
station_address.append(result[0]['formatted_address'])
station_address.insert(22, '대한민국 서울특별시 성북구 하월곡동 27-5')
station_address결과

문제 5
station_addreess 에 저장된 주소에서, 구만 따로 띄어냅니다. (예, 종로구)
그리고 따로 띄어낸 구를, crime_anal_police 에 '구별' 컬럼을 만들어서 넣습니다.
df.head()df['구별']= pd.Series(station_address).str.split().str[2]
df
address= '대한민국 서울 특별시 중구 수표로 17'
address.split()[3]
'중구'
new_list = []
for address in station_address :
print(address.split()[2])
new_list.append(address.split()[2])
df['구별'] = new_list
df결과
구글 API 를 적극적으로 사용하기
'Python > Pandas' 카테고리의 다른 글
| Pandas : 대중교통 / 범죄현황 / seaborn / pairplot (0) | 2022.05.04 |
|---|---|
| Pandas : pivot_table / Dates and Times/Frequencies and Offsets (0) | 2022.05.04 |
| pandas : Tindy Data / Bar Charts / Pie Charts /Histogram/Figures, Axes and Subplots/Heat Maps /seaborn/pairplot / cprr함수, 차트로 표현하기 (0) | 2022.05.03 |
| pandas : 기온데이터분석 / 히스토그램 (0) | 2022.05.03 |
| pandas : Series/Label&Index/NaN (0) | 2022.04.28 |



