
pandas의 pivot_table 익히기
1. 일단 df.to_csv('new_crime_in_Seoul.csv') 을 불러온다.
import pandas as pd
import numpy as np2. 피봇팅 한다. 즉 컬럼의 값을 열로 만드는것.
df = pd.read_excel('data/sales-funnel.xlsx')
# 인덱스를 중복된값으로 설정한것은 잘못 만든것이다.
# 중복데이터가 있으면 하나로 합쳐서 인덱스로 뽑되,
수치데이터만을 뽑아 평균데이터로 하나로 합치는것이다.
pd.pivot_table(df,index=['Name'] , aggfunc = np.max)pd.pivot_table(df,index=['Manager','Rep'],aggfunc= np.sum)
pd.pivot_table(df,index= ['Name'] , values = ['Price','Quantity'],aggfunc= np.sum)
pd.pivot_table( df, index=['Name'] , values= ['Price', 'Quantity'] , aggfunc=[np.sum, np.mean,np.std
범죄 데이터 구별로 정리하기
crime_anal = pd.read_csv('new_crime_in_Seoul.csv' , index_col=0)
crime_anal.head()
실습
인덱스를 '구별' 로 피봇팅 한다.
pd.pivot_table(crime_anal, index=['구별'])'강간검거율' , '강도검거율', '살인검거율', '절도검거율', '폭력검 거율' 을 계산하여, crime_anal에 각 컬럼을 추가한다. ( 검거율은 * 100 까지 한 값)
crime_anal['강간검거율'] = (crime_anal['강간 검거']/crime_anal['강간 발생'])*100
crime_anal['강도검거율'] = (crime_anal['강도 검거']/crime_anal['강도 발생'])*100
crime_anal['살인검거율'] = (crime_anal['살인 검거']/crime_anal['살인 발생'])*100
crime_anal['절도검거율'] = (crime_anal['절도 검거']/crime_anal['절도 발생'])*100
crime_anal['폭력검거율'] = (crime_anal['폭력 검거']/crime_anal['폭력 발생'])*100
crime_anal
이제 필요없는, '강간 검거' , '강도 검거', '살인 검거', '절도 검거', '폭력 검거' 컬럼을 제거한다.
crime_anal.drop(['강간 검거' , '강도 검거', '살인 검거', '절도 검거', '폭력 검거'],axis=1,inplace=True
crime_anal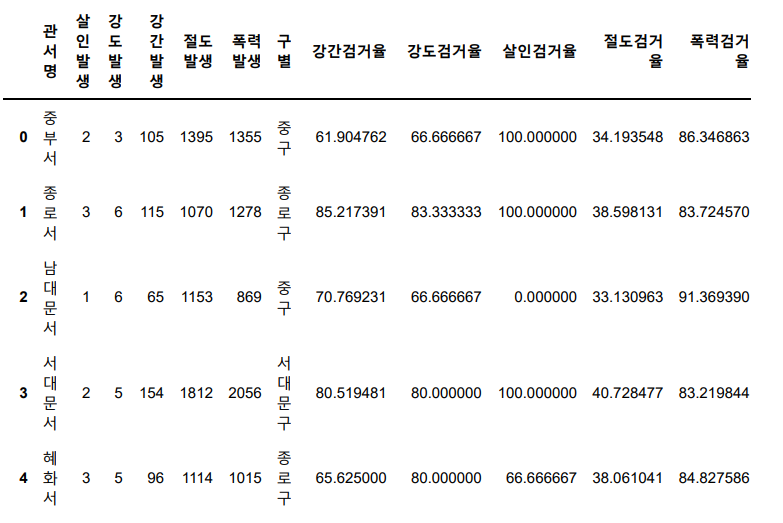
describe() 함수로 값을 확인해 보니, 검거율이 100 이상인 경우 도 있다. 따라서 100보다 크면, 100으로 값을 셋팅하세요.
crime_anal.describe()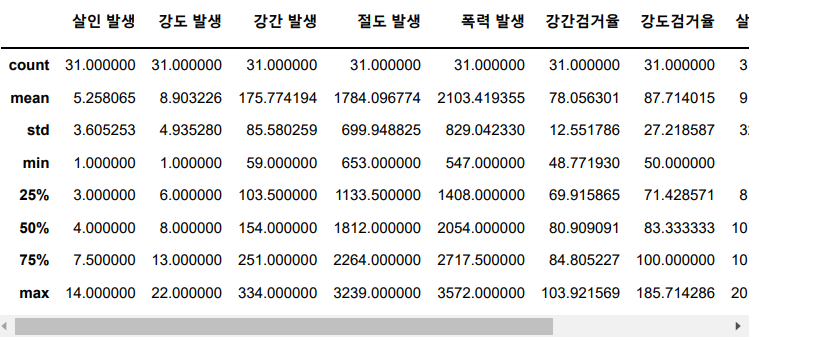
def over100(ratio):
if ratio > 100:
return 100
else:
return ratio
over100(10)결과값 : 10
crime_anal['강간검거율'] = crime_anal['강간검거율'].apply(over100)
crime_anal['강도검거율'] = crime_anal['강도검거율'].apply(over100)
crime_anal['살인검거율'] = crime_anal['살인검거율'].apply(over100)
crime_anal['절도검거율'] = crime_anal['절도검거율'].apply(over100)
crime_anal['폭력검거율'] = crime_anal['폭력검거율'].apply(over100)
crime_anal.describe()
crime_anal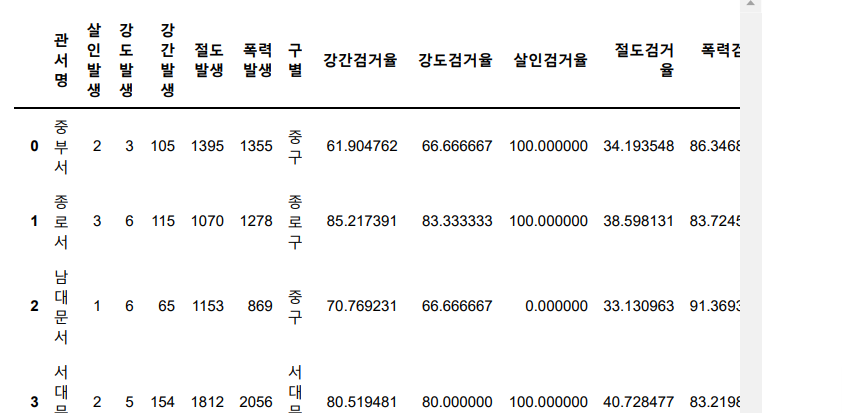
crime_anal.rename(columns={'강간 발생':'강간', '강도 발생':'강도', '살인 발생':'살인', '절도 발생':'절도')
crime_anal.head(3)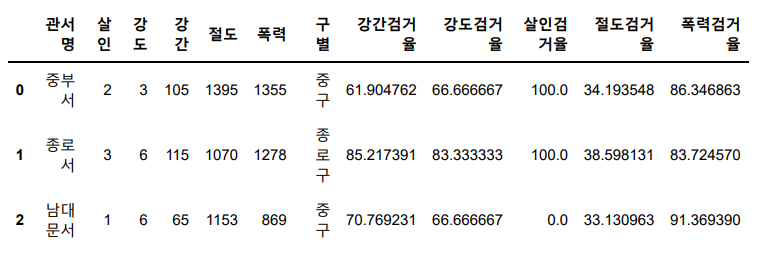
강간, 강도, 살인, 절도, 폭력을 노멀라이징 합니다.
데이터 노멀라이징 하는 이유는, 각각의 레인지를 통일하여, 해석하기 쉽게 하기 위함입니다.
from sklearn.preprocessing import StandardScaler, MinMaxScaler1. 표준화로 피쳐 스케일링
s_scaler = StandardScaler()
x_scaled1 = s_scaler.fit_transform(crime_anal[['강도','강간','살인','절도','폭력']])1. 정규화로 피쳐 스케일링
m_scaler = MinMaxScaler()
x_scaled2 = m_scaler.fit_transform(crime_anal[['강도','강간','살인','절도','폭력']])
crime_anal.head(3)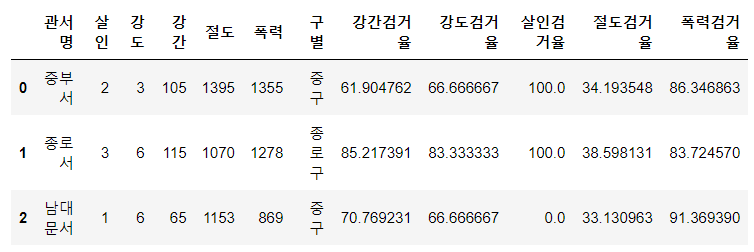
Dates and Times in Python
Native Python dates and times: datetime and dateutil
from datetime import datetime
someday = datetime(2022,5,11)
someday
#out
datetime.datetime(2022, 5, 11, 0, 0)
someday.isoformat()
#out
'2022-05-11T00:00:00'
someday.strftime('%Y-%m')
# out
'2022-05'
date_str = '2022-05-21'
from dateutil.parser import parse
someday = parse(date_str)
someday.weekday()
#out
5
날짜 하나는 가능한 코드
date_str_list = ['2022-05-11' , '2022-01-10' , '2022-07-03']
# 에러가 난다.아래 코드는 한개말고 여러가지로 한번에 바뀌길 원한다. 그래서 에러가뜬다.
[parse(date_str_list)]

for data in date_str_list :
print(parse(data))Typed arrays of times: NumPy's datetime64
기존의 파이썬 datetime 을 보강하기 위해, date 의 array 도 처리할 수 있게 numpy 에서 64-bit 로 처리하도록 라이브러리를 강화했음.
import numpy as np
any_date = np.array('2022-05-11' , dtype= np.datetime64)10일후를 알려주는 코드
any_date + 10out
numpy.datetime64('2022-05-21')-35일 후를 알려주는 코드
any_date - 35out
numpy.datetime64('2022-04-06')
any_date + np.arange(10) # 10일까지의 날짜를 알고싶다.
any_date + np.arange(10)out
array(['2022-05-11', '2022-05-12', '2022-05-13', '2022-05-14',
'2022-05-15', '2022-05-16', '2022-05-17', '2022-05-18',
'2022-05-19', '2022-05-20'], dtype='datetime64[D]')이것을 더 쉽게만든것이 판다스이다. 아래부터 시작한다.
Dates and times in pandas: best of both worlds
import pandas as pd
dates = ['2022-01-04' , '2022-01-07' , '2022-01-08' , '2022-01-22']
dates
#out
['2022-01-04', '2022-01-07', '2022-01-08', '2022-01-22']
dates1 = pd.to_datetime(dates)언뜻봐선 문자열 같지만, dtype='datetime64[ns]은 문자열이 아니다.라고 나온다.
dates1날짜로 10개를 만들어달라.
pd.to_timedelta(np.arange(10), 'D')
# out
TimedeltaIndex(['0 days', '1 days', '2 days', '3 days', '4 days', '5 days',
'6 days', '7 days', '8 days', '9 days'],
dtype='timedelta64[ns]', freq=None)한시간 단위로 나온다.
any_date + pd.to_timedelta(np.arange(10), 'h')
#out
DatetimeIndex(['2022-05-11 00:00:00', '2022-05-11 01:00:00',
'2022-05-11 02:00:00', '2022-05-11 03:00:00',
'2022-05-11 04:00:00', '2022-05-11 05:00:00',
'2022-05-11 06:00:00', '2022-05-11 07:00:00',
'2022-05-11 08:00:00', '2022-05-11 09:00:00'],
dtype='datetime64[ns]', freq=None)Pandas Time Series: Indexing by Time
dates
#out
['2022-01-04', '2022-01-07', '2022-01-08', '2022-01-22']
date_index = pd.DatetimeIndex(dates)
pd.Series(data=[20000, 35000, 18000, 22000], index= date_index)
#out
2022-01-04 20000
2022-01-07 35000
2022-01-08 18000
2022-01-22 22000
dtype: int64Regular sequences: pd.date_range() + Frequencies and Offsets
시작일과 종료일을 셋팅하면, 알아서 날짜를 채우도록 하는 함수
pd.date_range('2022-05-04', '2022-06-21') # 2022년 5월 4일부터 2022년 6월 21일까지 나타낸다.
#out
DatetimeIndex(['2022-05-04', '2022-05-05', '2022-05-06', '2022-05-07',
'2022-05-08', '2022-05-09', '2022-05-10', '2022-05-11',
'2022-05-12', '2022-05-13', '2022-05-14', '2022-05-15',
'2022-05-16', '2022-05-17', '2022-05-18', '2022-05-19',
'2022-05-20', '2022-05-21', '2022-05-22', '2022-05-23',
'2022-05-24', '2022-05-25', '2022-05-26', '2022-05-27',
'2022-05-28', '2022-05-29', '2022-05-30', '2022-05-31',
'2022-06-01', '2022-06-02', '2022-06-03', '2022-06-04',
'2022-06-05', '2022-06-06', '2022-06-07', '2022-06-08',
'2022-06-09', '2022-06-10', '2022-06-11', '2022-06-12',
'2022-06-13', '2022-06-14', '2022-06-15', '2022-06-16',
'2022-06-17', '2022-06-18', '2022-06-19', '2022-06-20',
'2022-06-21'],
dtype='datetime64[ns]', freq='D')
pd.date_range('2022-05-04', '2022-06-21', freq='w') # 주 단위.
#out
DatetimeIndex(['2022-05-08', '2022-05-15', '2022-05-22', '2022-05-29',
'2022-06-05', '2022-06-12', '2022-06-19'],
dtype='datetime64[ns]', freq='W-SUN')
date_index = pd.DatetimeIndex(dates), freq='W-WED')
#out
DatetimeIndex(['2022-05-04', '2022-05-11', '2022-05-18', '2022-05-25',
'2022-06-01', '2022-06-08', '2022-06-15'],
dtype='datetime64[ns]', freq='W-WED')'Python > Pandas' 카테고리의 다른 글
| Pandas : 대중교통 / 범죄현황 / seaborn / pairplot (0) | 2022.05.04 |
|---|---|
| pandas : Google Map API(Geocoding API 설정방법) /csv file 불러오기 / encoding (0) | 2022.05.03 |
| pandas : Tindy Data / Bar Charts / Pie Charts /Histogram/Figures, Axes and Subplots/Heat Maps /seaborn/pairplot / cprr함수, 차트로 표현하기 (0) | 2022.05.03 |
| pandas : 기온데이터분석 / 히스토그램 (0) | 2022.05.03 |
| pandas : Series/Label&Index/NaN (0) | 2022.04.28 |



