Amazon Echo Reviews Analysis
- 데이터셋은 아마존의 알렉사 제품에 대한, 3000개의 리뷰로 되어있습니다.
- 컬럼은 rating, date, variation(제품모델), verified_reviews, feedback
- Dataset: www.kaggle.com/sid321axn/amazon-alexa-reviews
Hierarchical Clustering
Library imfort
실행하기
import numpy as np
import matplotlib.pyplot as plt
import pandas as pddataset 읽어오기
df = pd.read_csv('data/Mall_Customers.csv')
X = df.iloc[:, 3:]
X.head()
Dendrogram 을 그리고, 최적의 클러스터 갯수를 찾아보자.
import scipy.cluster.hierarchy as sch
sch.dendrogram( sch.linkage(X, method='ward') )
plt.title('Dendrogram')
plt.xlabel('Customers')
plt.ylabel('Eculidaen Distances')
plt.show()
X.shapeout
(200, 2)Training the Hierarchical Clustering model
from sklearn.cluster import AgglomerativeClustering
hc = AgglomerativeClustering(n_clusters=5)
y_pred = hc.fit_predict(X)
df['Group'] = y_pred
df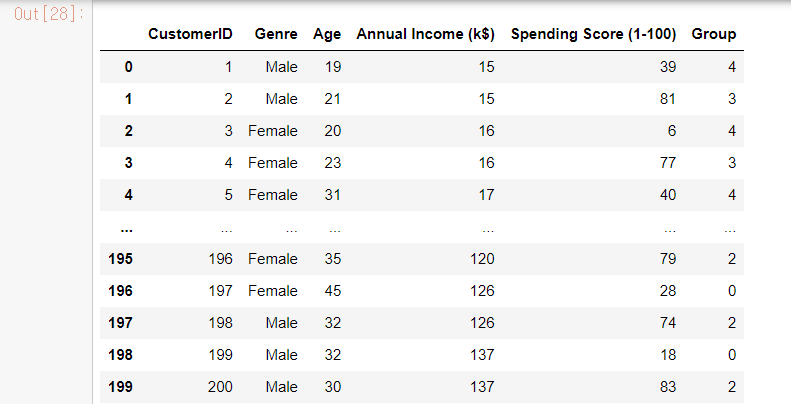
그루핑 정보를 확인 ( # hc 용 )
# hc 용
plt.scatter(X.values[y_pred == 0, 0], X.values[y_pred == 0, 1], s = 100, c = 'red', label = 'Cluster 1')
plt.scatter(X.values[y_pred == 1, 0], X.values[y_pred == 1, 1], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(X.values[y_pred == 2, 0], X.values[y_pred == 2, 1], s = 100, c = 'green', label = 'Cluster 3')
plt.scatter(X.values[y_pred == 3, 0], X.values[y_pred == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4')
plt.scatter(X.values[y_pred == 4, 0], X.values[y_pred == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()




