문자열 데이터를 숫자로 바꿔주는 CountVectorizer와 analyzer파라미터
analyzer 파라미터는 학습단위를 결정하는 파라미터입니다.
word, char 2가지 옵션 정도를 고려해볼 수 있습니다.
analyzer = 'word'라고 설정시, 학습의 단위를 단어로 설정합니다. (ex - home, go, my ...)
analyzer = 'char'라고 설정시, 학습의 단위를 글자로 설정합니다.(ex - a, b, c, d ...)나이브 베이즈를 이용한 스팸 분류
PROBLEM STATEMENT
5,574개의 이메일 메시지가 있으며, 스팸인지 아닌지의 정보를 가지고 있다.
컬럼 : text, spam
spam 컬럼의 값이 1이면 스팸이고, 0이면 스팸이 아닙니다.
스팸인지 아닌지 분류하는 인공지능을 만들자 - 수퍼바이즈드 러닝의 분류 문제!STEP #0: LIBRARIES IMPORT
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlineSTEP #1: IMPORT DATASET
emails.csv 읽기
in
from google.colab import drive
drive.mount('/content/drive')out
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).구글 드라이브에 호환하는 방법
import os
os.chdir('/content/drive/MyDrive/Colab Notebooks')
pd.read_csv('emails.csv')
spam_df = pd.read_csv('emails.csv')
spam_df.head()STEP #2: VISUALIZE DATASET
스팸은 몇개이고, 아닌것은 몇개인지 확인하시오.
spam_df.head(3)
spam_df.shape
#####out
(5728, 2)
sns.countplot(data= spam_df, x = 'spam')
plt.show()in
spam_df['spam'].value_counts()out
0 4360
1 1368
Name: spam, dtype: int64이메일의 길이가 스팸과 관련이 있는지 확인해 보려 합니다. 이메일의 문자 길이를 구해서, length 라는 컬럼을 만드세요.
spam_df['text'][0]spam_df['spam'][0]
########out
1
spam_df['length'] = spam_df['text'].str.len()
spam_df.head(3)out
글자 길이를 히스토그램으로 나타내시오.
spam_df['length'].hist()
plt.show()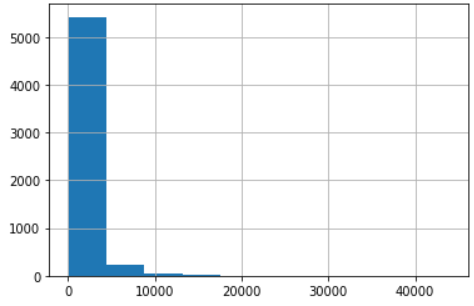
in
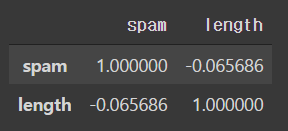
spam_df.corr()out
가장 긴 이메일을 찾아서 스팸인지 아닌지 확인하고, 이메일 내용을 확인하시오.
in
spam_df.loc[ spam_df['length'] == spam_df['length'].max() , ]out
2650 Subject: from the enron india newsdesk - april... 0 43952spam_df.loc[ spam_df['length'] == spam_df['length'].max() , 'text' ][2650]
#########out
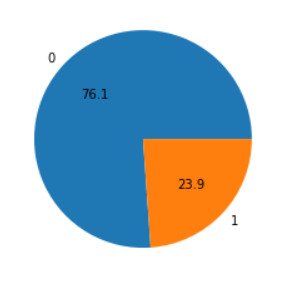
Subject: from the enron india newsdesk - april 27 th newsclips fyi news articles from indian press . - - - - - - - - - - - - - - - - - - - - - - forwarded by sandeep kohli / enron _ development on 04 / 27 / 2001 08 : 24 am - - - - - - - - - - - - - - - - - - - - - - - - - - - nikita varma 04 / 27 / 2001 07 : 51 am to : nikita varma / enron _ development @ enron _ development cc : ( bcc : sandeep kohli / enron _ development ) subject : from the enron india newsdesk - april 27 th newsclips friday apr 27 2001 , http : / / www . economictimes . com / today / cmo 3 . htm dpc board empowers md to cancel mseb contract friday apr 27 2001 , http : / / www . economictimes . com / today / 27 compl 1 . htm mseb pays rs 134 cr under \' protest \' to dpc friday , april 27 , 001 , http : / / www . businessstandard . com / today / economy 4 . asp ? menu = 3 enron india md authorised to terminate ppa friday , april 27 , 2001 , http : / / www . financialexpress . com / fe 20010427 / topl .0은 스팸이 아니고, 1은 스팸입니다. 파이차트를 통해, 스팸과 스팸이 아닌것이 몇 퍼센트인지, 소수점 1자리 까지만 보여주세요.
spam_count = spam_df['spam'].value_counts()
spam_count
#####out
0 4360
1 1368
Name: spam, dtype: int64
plt.pie(spam_count, autopct='%.1f', labels = spam_count.index)
plt.show()out
스팸이 아닌것은 ham 변수로, 스팸인것은 spam 변수로 저장하시오.
ham = spam_df.loc[ spam_df['spam'] == 0 , ]
spam = spam_df.loc[ spam_df['spam'] == 1 , ]
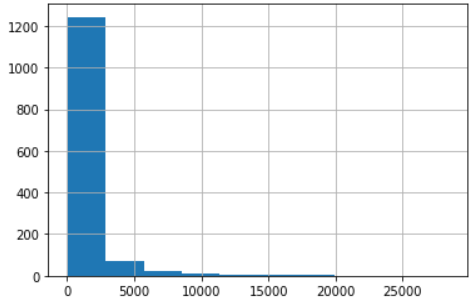
# 스팸의 이메일 길이를 히스토그램으로 나타내시오.
spam['length'].hist()
plt.show()out
# 햄의 이메일 길이를 히스토그램으로 나타내시오.
ham['length'].hist()
plt.show()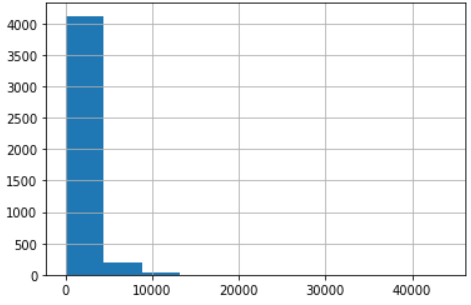
STEP #3: CREATE TESTING AND TRAINING DATASET/DATA CLEANING
STEP 3.1 쉼표, 마침표 등의 구두점 제거하기
spam_df
Test = 'Hello Mr. Future, I am so happy to be learning AI now~'
import string
string.punctuation'Python > Machine Learning' 카테고리의 다른 글
| python pandas resample (0) | 2022.05.12 |
|---|---|
| Machine Learning : Hierarchical Clusting의 Dendrogram 설명 (0) | 2022.05.09 |
| Machine Learning : K-means 의 WCSS와 Elbow Method 설명 (0) | 2022.05.09 |
| Machine Learning : WordCloud 라이브러리 사용법과 Stopwords 적용하는 방법 (0) | 2022.05.09 |
| Machine Learning : Hierarchical Clustering (0) | 2022.05.09 |



