Machine Learning : K-means 의 WCSS와 Elbow Method 설명
클라우드 기반 인공지능 개발과 DevOps2022. 5. 9. 17:48
K-Means Clustering
Unsupervised Learning 이다.
k 개의 그룹을 만든다. 즉, 비슷한 특징을 갖는 것들끼리 묶는것.
- 다음을 두개, 세개, 네개 그룹 등등 원하는 그룹으로 만들 수 있다.
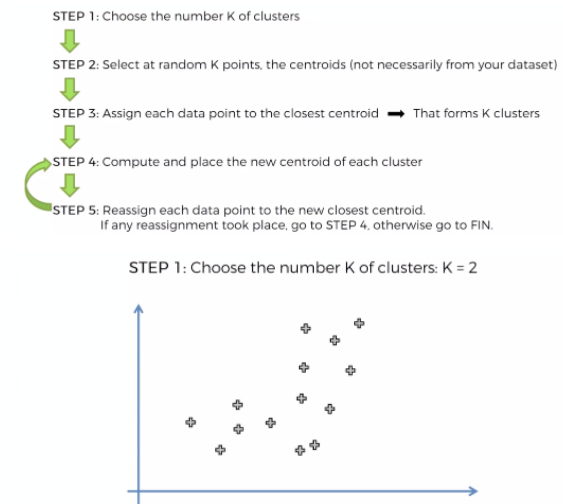
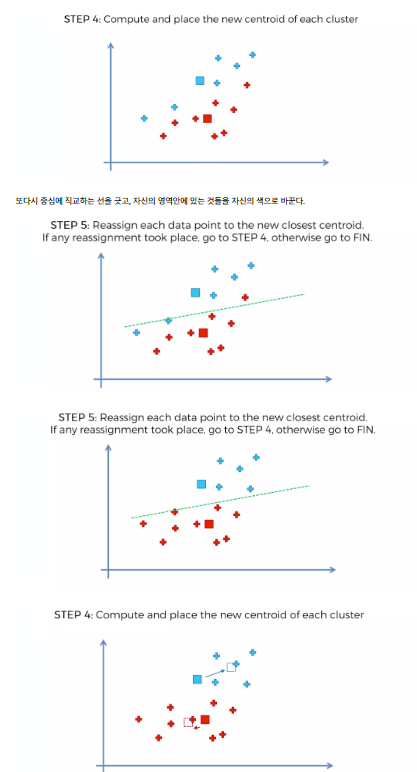
알고리즘
Random Initialization Trap
다음과 같은 데이터 분포가 있다고 치자.
우리가 원하는 클러스터링 그룹화는, 아래와 같은 것이다.
원치 않는 그룹화가 되어버렸다!
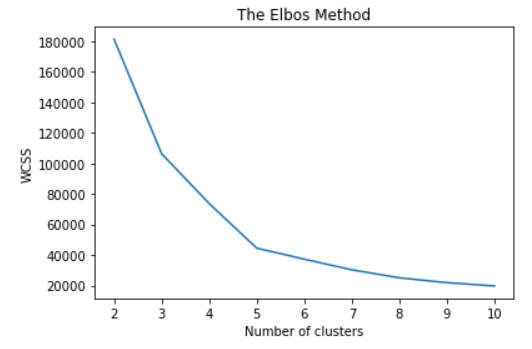
Choosing the right number of clusters
몇개로 분류할지는 어떻게 결정하는가? K의 갯수를 정하는 방법
within-cluster sums of squares
센터가 원소들과의 거리가 멀수록 값이 커진다. 따라서 최소값에 가까워지는 갯수를 뽑되, 갯수가 너무 많아지면 차별성이 없어진다.
# Unsupervised learning
# 중심과의 거리가 짧을수록 비슷한 속성이다.
#WCSS
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sb
df = pd.read_csv('data/Mall_Customers.csv')
df.isna().sum()
CustomerID 0
Genre 0
Age 0
Annual Income (k$) 0
Spending Score (1-100) 0
dtype: int64